|
I am a research staff at Ant Research for human-centered Spatial AI. Before that, I was a post-doc researcher with Yebin Liu at Tsinghua University. In 2022, I obtained a PhD degree from INRIA Rhône-Alpes & Université Grenoble Alpes (France) under the supervision of Edmond Boyer and Jean-Sébastien Franco for the research of 3D vision. During my PhD, I was working closely with HoloLens team of Microsoft Zürich & Cambridge. In 2018, I received an Engineer degree from Ecole Polytechnique (France) and a Master's degreee from Paris-Saclay University (France) in Data Sciences. Prior to that, I graduated from Tongji University (China). We are hiring interns for research purpose. contact: zhouboyao.2023@tsinghua.org.cn |

|
|
|

|
Zijian Wu, Boyao Zhou#, Liangxiao Hu, Hongyu Liu, Yuan Sun, Xuan Wang, Xun Cao, Yujun Shen, and Hao Zhu (Project lead#) Computer Vision and Pattern Recognition (CVPR2026) / Project page We present UIKA, a fast feed-forward 3D Gaussian Head Avatar by taking an arbitrary number of pose-free images as input. |

|
Boyao Zhou, Shunyuan Zheng, Zhanfeng Liao, Zihan Ma, Hanzhang Tu, Boning Liu, and Yebin Liu AAAI Conference on Artificial Intelligence (AAAI2026) / Project page We introduce Splat-SAP, a feed-forward 3D Gaussian Splatting with scale-aware point map reconstruction. |
|
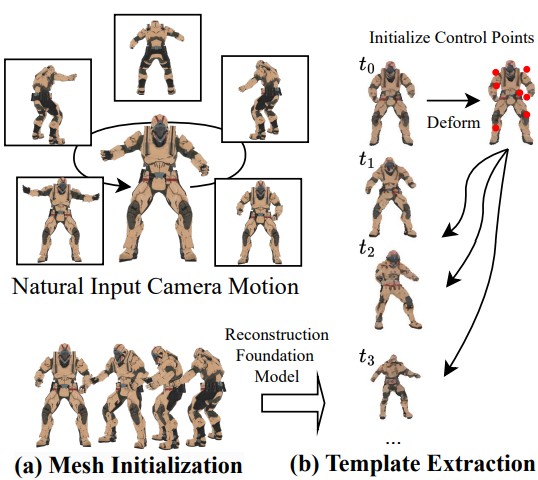
Shuohan Tao, Boyao Zhou, Hanzhang Tu, Yuwang Wang, and Yebin Liu International Conference on 3D Vision (3DV2026) / We propose Tessellation GS, a structured 2D GS approach anchored on mesh faces, to reconstruct dynamic scenes from a single continuously moving or static camera. |

|
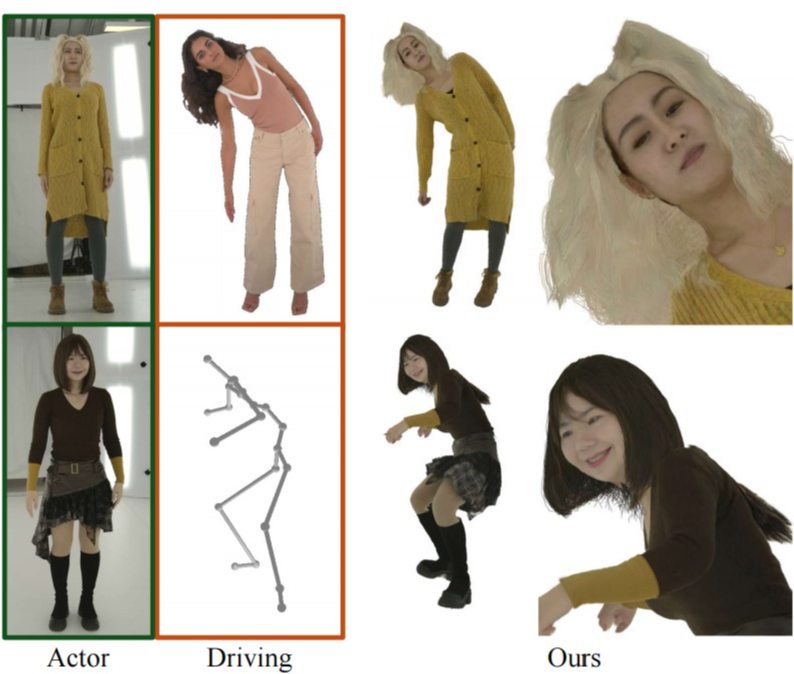
Boyao Zhou*, Shunyuan Zheng*, Hanzhang Tu, Ruizhi Shao, Boning Liu, Shengping Zhang, Liqiang Nie, and Yebin Liu (Equal contribution*) IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI2025) / Project page / Code We present GPS-Gaussian+, a generalizable 3D Gaussian Splatting, for human-centered scene rendering from sparse views in a feed-forward manner. |
|
Zhanfeng Liao, Hanzhang Tu, Cheng Peng, Hongwen Zhang#, Boyao Zhou#, and Yebin Liu# (Corresponding author#) International Conference on Computer Vision (ICCV2025) / We introduce HADES, the first framework to seamlessly integrate dynamic hair into human avatars. |
|
|
Zhanfeng Liao, Yuelang Xu, Zhe Li, Qijing Li, Boyao Zhou, Ruifeng Bai, Di Xu, Hongwen Zhang, and Yebin Liu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI2025) / Project page We propose HHAvatar represented by controllable 3D Gaussians for high-fidelity head avatar with dynamic hair modeling. |

|
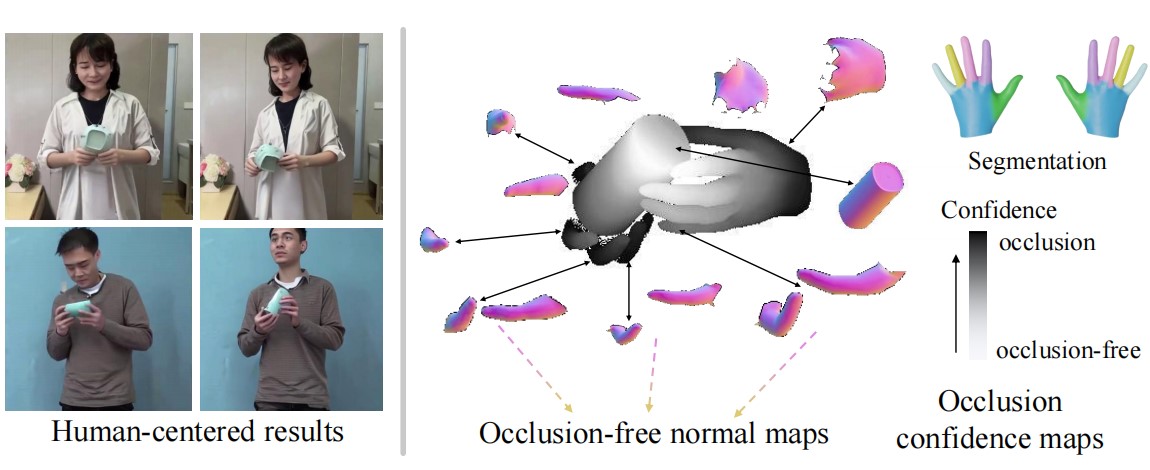
Jiajun Zhang, Yuxiang Zhang, Hongwen Zhang, Xiao Zhou, Boyao Zhou, Ruizhi Shao, Zonghai Hu, and Yebin Liu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI2025) / Project page / Code We present Ins-HOI, a novel method for instance-level humans/hands and objects interaction recovery. |
|
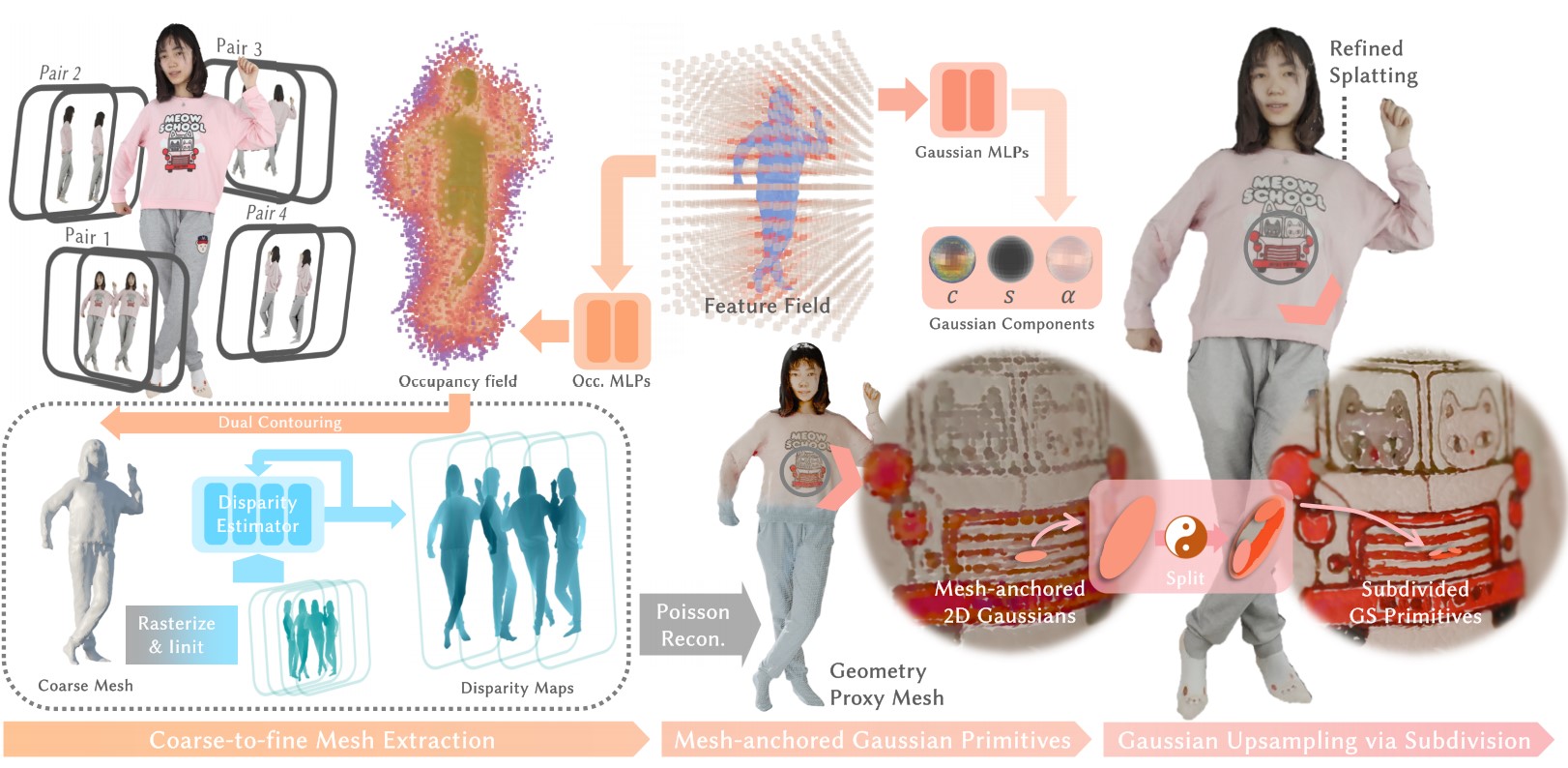
Hanzhang Tu, Zhanfeng Liao, Boyao Zhou#, Shunyuan Zheng, Xilong Zhou#, Liuxin Zhang, Qianying Wang, and Yebin Liu# (Corresponding author#) Computer Vision and Pattern Recognition (CVPR2025) / We present a full-body human digitalization pipeline for both geometry and appearence with 2D surfel Gaussian Splatting. |
|
Youxin Pang, Ruizhi Shao, Jiajun Zhang, Hanzhang Tu, Yun Liu, Boyao Zhou, Hongwen Zhang, and Yebin Liu Computer Vision and Pattern Recognition (CVPR2025 Highlight) / We propose a novel framework for generalizable and dexterous hand-object manipulation video generation. |

|
Hanzhang Tu, Ruizhi Shao, Xue Dong, Shunyuan Zheng, Hao Zhang, Lili Chen, Meili Wang, Wenyu Li, Siyan Ma, Shengping Zhang, Boyao Zhou#, and Yebin Liu# (Corresponding author#) SIGGRAPH2024 Conference Proceedings / Project page We present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. |

|
Shunyuan Zheng, Boyao Zhou, Ruizhi Shao, Boning Liu, Shengping Zhang, Liqiang Nie, and Yebin Liu Computer Vision and Pattern Recognition (CVPR2024 Highlight) / Project page / Code We propose GPS-Gaussian, a generalizable pixel-wise 3D Gaussian representation for synthesizing novel views of any unseen characters instantly without any fine-tuning or optimization. |

|
Ruizhi Shao, Jingxiang Sun, Cheng Peng, Zerong Zheng, Boyao Zhou, Hongwen Zhang, and Yebin Liu Computer Vision and Pattern Recognition (CVPR2024) / Project page We introduce Control4D, an innovative framework for editing dynamic 4D portraits using text instructions. |
|
|
Liangxiao Hu, Hongwen Zhang, Yuxiang Zhang, Boyao Zhou, Boning Liu, Shengping Zhang, and Liqiang Nie Computer Vision and Pattern Recognition (CVPR2024) / Project page / Code We present GaussianAvatar, an efficient approach to creating realistic human avatars with dynamic 3D appearances from a single video. |
|
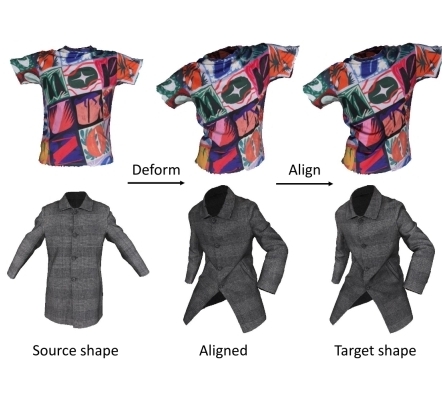
Siyou Lin, Boyao Zhou, Zerong Zheng, Hongwen Zhang, and Yebin Liu International Conference on Computer Vision (ICCV2023) / Project page / Code We leverage intrinsic manifold properties and neural deformation fields with a coarse-to-fine two-stage method for non-rigid garment alignment. |

|
Zhe Li, Zerong Zheng, Yuxiao Liu, Boyao Zhou, and Yebin Liu SIGGRAPH2023 Conference Proceedings / Project page / Code We propose a neural avatar representation with optimal pose embeddings for learning the dynamic human appearance. |
|
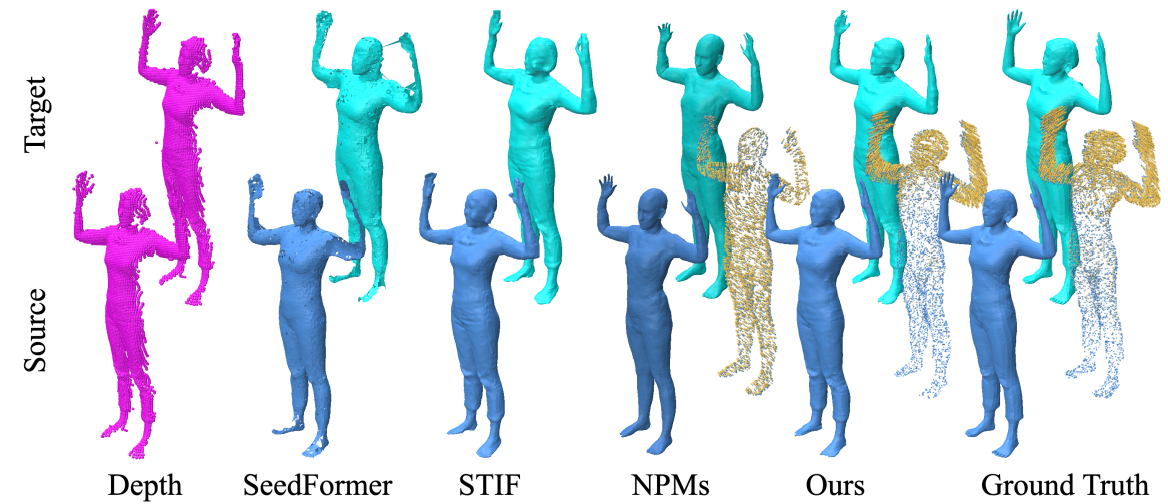
Boyao Zhou, Di Meng, Jean-Sébastien Franco, and Edmond Boyer Computer Vision and Pattern Recognition (CVPR2023) We jointly learn human shape and flow with implicit representation for completing human shapes from partial observation. |
|
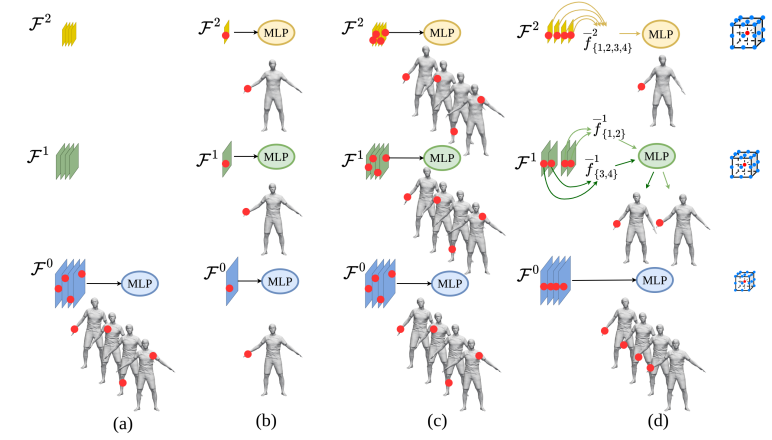
Boyao Zhou, Jean-Sébastien Franco, Martin Delagorce, and Edmond Boyer Asian Conference on Computer Vision (ACCV2022) /Code We propose to complete human shapes in a coarse-to-fine manner from both spatial and temporal directions. |
|
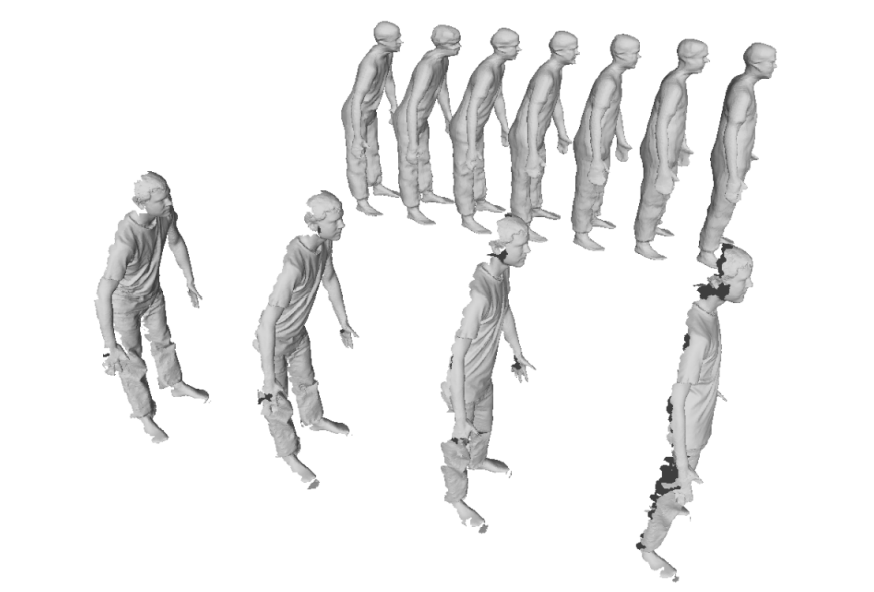
Boyao Zhou, Jean-Sébastien Franco, Federica Bogo, and Edmond Boyer International Conference on 3D Vision (3DV2021) We propose to learn a continuous implicit representation of human shapes from a sequence of partial observations. |
|
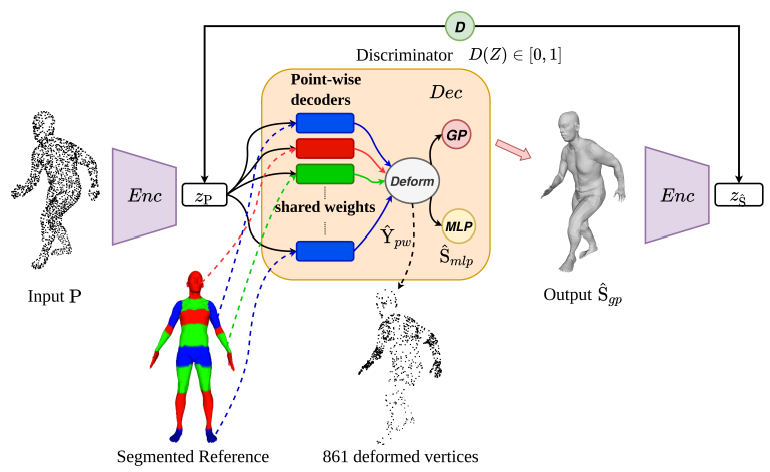
Boyao Zhou, Jean-Sébastien Franco, Federica Bogo, Bugra Tekin, and Edmond Boyer Asian Conference on Computer Vision (ACCV2020) We propose to reconstruct template-aligned human shapes with adversarial Gaussian Process Network from sparse point clouds. |
|
Fei Song, Boyao Zhou, Quan Sun, Wang Sun, Shiwen Xia, and Yanlei Diao BIRTE2018 |
|
PhD thesis
|
|
|
|
Page adapted from this website. |